

评分:
好评:
差评:
手机扫描下载
MultiTTS共存版是一款语音引擎工具,能够与各类小说应用及阅读软件配合,实现免费听书功能。该版本采用独立签名设计,可与官方版本同时安装使用,互不干扰。软件内置丰富多样的AI语音包,支持在线与离线两种使用模式,方便用户随时将文本转换为自然流畅的语音输出,也适合喜欢自定义规则的用户进行个性化设置。

1. 获取MultiTTS应用及所需的语音包文件。
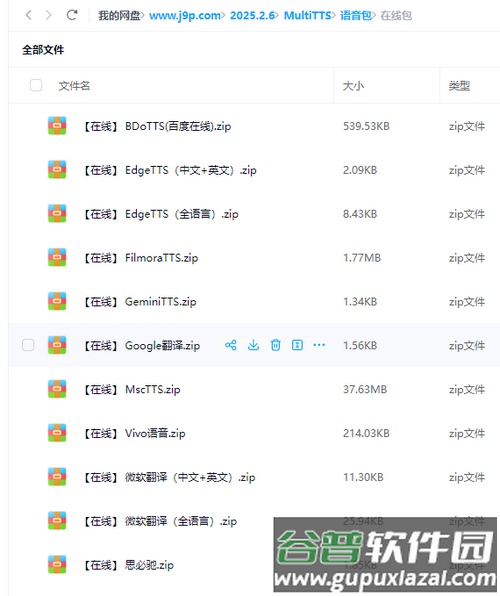
2. 安装完成后,点击界面右上角的导入功能;若没有反应,可尝试执行重载操作。
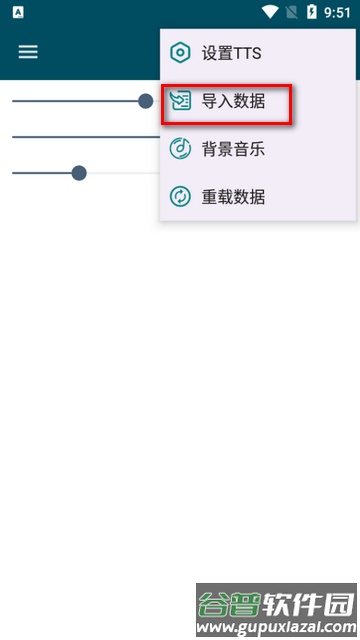
3. 打开左上角的软件设置菜单;若感觉运行卡顿,可启用转发器功能,流畅情况下则无需调整。
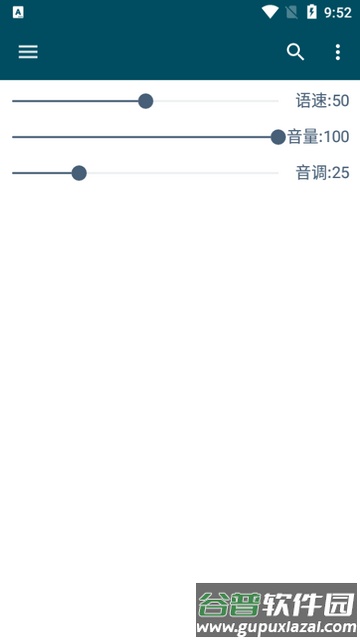
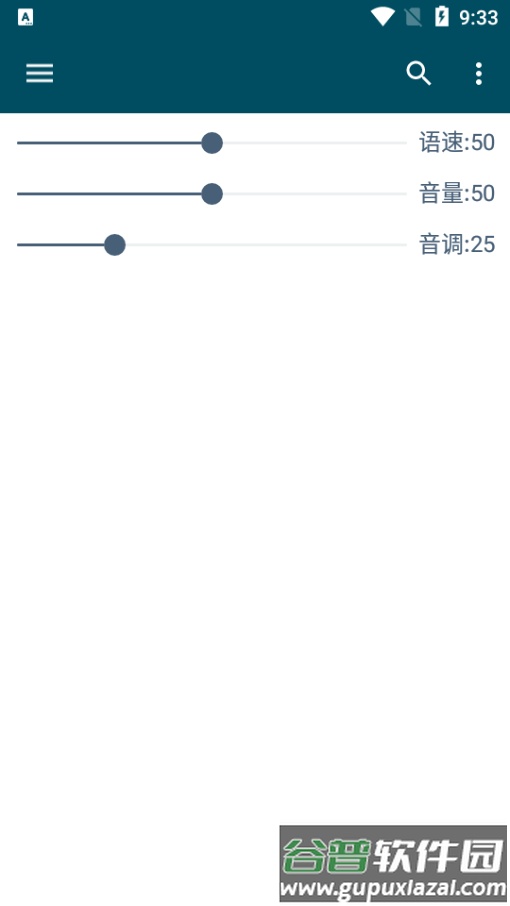
4. 单击即可选择发音声音;长按发音人头像区域,可以调节语速与音调参数。
5. 提前准备好需要朗读的小说文件,例如TXT格式文档。
6. 进入软件设置,开启合成功能、转发器以及文本解析选项;系统通常会在角色管理模块自动生成对应的适配角色。
7. 返回声音列表界面,单击设定旁白声音,长按声音字母区域可将其指定为对话语音。
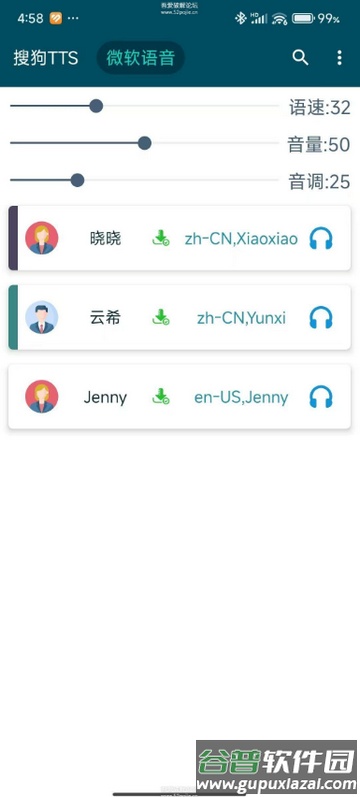
8. 进入角色管理界面查看当前配置。
9. 打开角色池功能,选取若干适配的男女声音角色。
10. 启动阅读类应用,开始朗读并进入设置,将朗读引擎切换为MultiTTS转发器,试听几分钟。
11. 重新打开MultiTTS,进入角色池,在右侧分配表中按照个人偏好调整声音匹配关系。
12. 也可以为故事中特定的角色单独分配合适的声音。
共存版采用不同的应用签名,能够与官方原版在同一设备上并行安装与使用;当你对当前版本感到满意,同时又想体验新版本功能却担心其稳定性时,可以先安装共存版进行试用,确认效果后再决定是否升级原版应用。
1. 在软件左上角菜单中找到并开启“转发服务”选项。
2. 进入软件设置中的播放设置板块,打开“流式传输”开关。
3. 在其他设置里点击“添加至阅读”功能,并按照提示确认操作。
4. 打开已安装的阅读应用,选择一本书开始朗读,在朗读设置中将引擎更改为“MultiTTS・转发器”。
经过以上配置,可以实现段落之间几乎无间隔的连贯朗读效果;流式传输本身能减少间隔,结合转发器使用则能进一步将间隔时间降至极低水平。
单击可选择或取消选择主合成引擎。
长按可设定或取消设定对话合成引擎。
长按发音人头像能进入编辑界面调整参数。
长按已下载图标可删除对应的发音人数据。
按住发音人名称上下拖动能调整排列顺序。
在发音人名称上左右滑动可执行删除操作。
其他列表同样支持滑动删除与拖动排序。
在主界面列表顶部下拉,会显示批量管理界面。
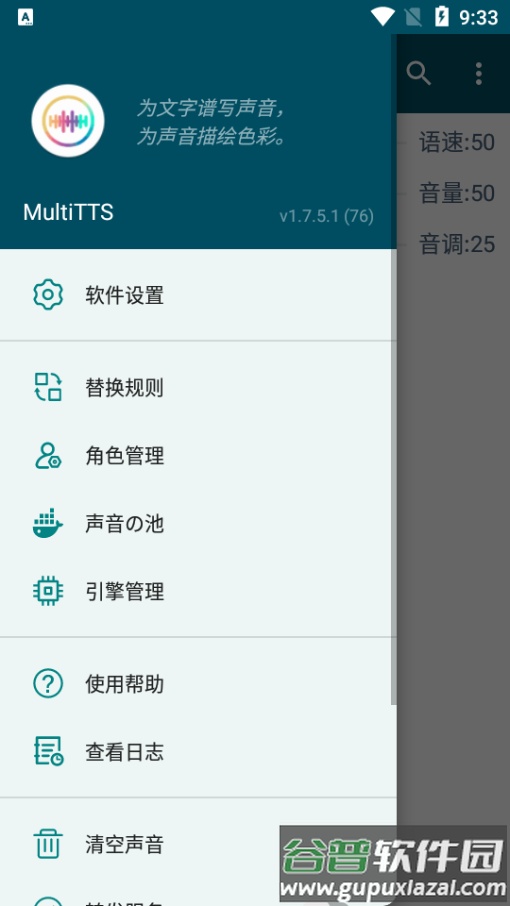
导入数据:选择包含引擎数据的压缩包导入,要求压缩包根目录存在合法的config.yaml配置文件。
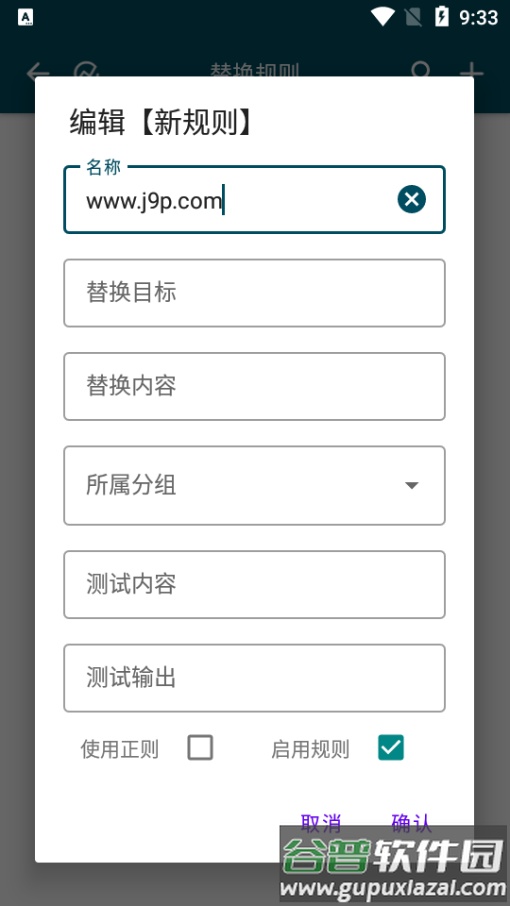
编辑替换:在此界面可修正单词发音,支持常规替换与正则表达式替换两种方式。
背景音乐:能在语音合成的同时播放背景音乐。
角色管理:通过添加规则,识别朗读文本中的角色,并使用指定发音人进行朗读。
声音の池:为每个匹配到的抽象角色,从其关联的声音分组中随机分配一个具体声音。
引擎管理:提供引擎的编辑、添加、删除、排序及数据导出功能。
重载数据:重新读取配置文件并加载数据,默认从设备数据库中加载信息。
角色名称:需要匹配的特定角色名称。
角色正则:用于匹配角色名的正则表达式,留空时直接使用角色名称进行匹配。
抽象角色:未启用时,所有匹配角色使用同一声音;启用后代表此为抽象角色,其下属具体人物将从声音池分配不同声音。
前向匹配:规则将匹配对话发生前的文本内容。
后向匹配:规则将匹配对话结束后的文本内容。
文本:匹配符合正则表达式的全部文本内容。
语言:匹配符合选定语言类别的文本。
角色:匹配对话内容对应的说话者身份。
在角色管理界面,长按添加按钮可为候选语种设置发音人。
软件会优先执行所有前向匹配,仅当前向无结果时,才进行后向匹配。
类型:当前仅支持添加HTTP类型的引擎。
代号:引擎的内部标识,建议使用字母、数字及下划线组合。
请求头:发送HTTP请求时所携带的头部信息。
URL:HTTP链接地址,其中若包含JavaScript表达式需用双大括号包裹。
voiceCode:发音人代号。
speakText:待合成的文本内容。
speakSpeed:语速数值,范围在0至100之间。
speakVolume:音量数值,范围在0至100之间。
params:参数数组,对应发音人的各项参数,已进行分割处理。
抽象角色:在角色管理中已定义的抽象角色类别。
角色声音:每个抽象角色对应的具体人物,会从同组声音中随机分配一个使用。
角色匹配规则:用于在匹配对话角色时,筛选出有效的上下文;其中__ROLE__指代目标角色,__OTHER__指代其他角色。
语法结构分析:输入文本后可进行词性标注,解析句子语法结构;具体词性表可参见帮助文档末尾部分。
自动分配声音:识别到人物后,自动从角色池选择声音进行分配;分配关系会被缓存,直至被新记录覆盖。
文本人物分析:分析文本中出现的新词,该过程耗时较长;分析完成后点击保存,将在角色管理中生成对应角色。
人物名称正则:在文本人物分析中,用于筛选分析结果,过滤出符合人名特征的词汇。
语音合成接口位于 http://localhost:8774/forward ,支持GET参数如下:
text:需要合成的文本。
speed:语速,取值0到100。
volume:音量,取值0到100。
pitch:音高,取值0到100。
voice:声音ID,可通过请求/voices接口获取全部发音人列表。
语音列表接口为 http://localhost:8774/voices ,无需附加参数。
若需在文本中手动指定说话人,可在对话内容的引号内使用双尖括号包裹人名;例如:“<<张三>>这句话是我说的。”
如果应用在后台被关闭,请检查并设置电池优化、后台运行、关联启动及阻止休眠等相关权限。
导入压缩包时若错误信息包含zip关键词,可能是下载过程中文件损坏所致。
软件发生崩溃时,日志会自动复制到剪贴板;反馈问题时请提供完整的日志内容。
文本转语音:将文本内容转换为语音朗读,支持TXT、PDF、EPUB等多种文档格式,方便用户在阅读时切换为语音播放。
语音包管理:用户可以自由下载并管理不同的AI语音包,根据需求选择合适的音色与语言类型。
离线下载:支持语音包离线下载,用户可在网络通畅时提前下载资源,之后在无网络环境下照常使用。
音色切换:允许在不同语音包之间自由切换,随时调整朗读音色,适应不同的使用场景或个人听感偏好。
朗读控制:提供播放、暂停、快进、后退等基础控制功能,用户可轻松管理朗读进度,并调节语速与音量大小。
数据重载:若覆盖更新后发音人未正常显示,可通过右上角菜单选择“重载数据”来恢复语音包列表。
修复了已知的若干问题。
更新Sherpa-onnx库,现已支持matcha与kokoro类型的模型;不过当前sherpa-onnx对kokoro多语言模型的支持仍存在一些局限。
新增印尼语翻译,由novan Galaxy提供支持。











 疯狂阅读免费小说官方版 v2024安卓版v疯狂阅读免费小说官方版 v2024安卓版
疯狂阅读免费小说官方版 v2024安卓版v疯狂阅读免费小说官方版 v2024安卓版 中国摄协appv1.4.2
中国摄协appv1.4.2 幻漫漫画官方版v3.1.2
幻漫漫画官方版v3.1.2 ACE动漫APP 安卓版v2.4
ACE动漫APP 安卓版v2.4 漫画岛app官方正版 安卓版v1.2
漫画岛app官方正版 安卓版v1.2 青空文库安卓手机版 安卓版V9.0.62
青空文库安卓手机版 安卓版V9.0.62 包子漫画app免费漫画v1.0.31
包子漫画app免费漫画v1.0.31 希望阅读appv1.0.1
希望阅读appv1.0.1 换源阅读器免费版v1.5
换源阅读器免费版v1.5
最新评论